“Have no fear of perfection—you’ll never reach it.” ~Salvador Dalí
We live in a world that worships polish.
Perfect photos on Instagram. Seamless podcasts with no awkward pauses. Articles that read like they’ve passed through a dozen editors.
And now, with AI tools that can produce mistake-free writing in seconds, the bar feels even higher. Machines can generate flawless sentences, perfect grammar, and shiny ideas on demand. Meanwhile, I’m over here second-guessing a paragraph, rewriting the same sentence six different ways, and still wondering if “Best” or “Warmly” is the less awkward email sign-off.
It’s easy to feel like our messy, human work doesn’t measure up.
I’ve fallen into that trap plenty of times. I’ve delayed publishing because “it’s not ready.” I’ve rerecorded podcasts because I stumbled on a word. I’ve tweaked and reformatted things no one else would even notice.
Perfectionism whispers: If it isn’t flawless, don’t share it.
But over time, I’ve learned something else: imperfection is not a liability. It’s the whole point.
A Table Full of Flaws
One of the best lessons I’ve ever learned about imperfection came not from writing or technology, but from woodworking.
About a decade ago, I decided to build a dining table. I spent hours measuring, cutting, sanding, and staining. I wanted it to be perfect.
But here’s the truth about woodworking: nothing ever turns out perfect. Ever.
That table looks solid from across the room. But if you step closer, you’ll notice the flaws. The board I mismeasured by a quarter inch. The corner I over-sanded. The stain that didn’t set evenly.
At first, I saw those flaws as failures. Proof that I wasn’t skilled enough, patient enough, or careful enough.
But then something surprising happened. My wife walked into the room, saw the finished table, and said she loved it. She didn’t see the mistakes. She saw something that had been made with love and care.
And slowly, I began to see it that way, too.
That table isn’t just furniture. It’s proof of effort, process, and patience. It carries my fingerprints, my sweat, and my imperfect humanity.
And here’s the kicker: it’s way more fulfilling than anything mass-produced or manufactured as machine-perfect.
Why Imperfection Connects Us
That table taught me something AI never could: flaws tell a story.
Machines can produce flawless outputs, but they can’t create meaning. They can’t replicate the pride of sanding wood with your own hands or the laughter around a table that wobbled for the first month.
Imperfections are what make something ours. They carry our fingerprints, quirks, and lived experiences.
In contrast, perfection is sterile. It might be impressive, but it rarely feels alive.
Think about the things that move us most—a friend’s vulnerable story, a laugh that turns into a snort, a talk where the speaker loses their train of thought but recovers with honesty. When was the last time you felt closest to someone? Chances are, it wasn’t when they were polished, it was when they were real. Those moments connect us precisely because they are imperfect.
They remind us we’re not alone in our flaws.
The AI Contrast
AI dazzles us because it never stutters. It never doubts. It never sends an awkward text or spills coffee on its keyboard. AI can do flawless. But flawless isn’t the same as meaningful.
But here’s what it doesn’t do:
It doesn’t feel the mix of pride and embarrassment in showing someone your wobbly table.
It doesn’t understand the joy of cooking a meal that didn’t go exactly to plan.
It doesn’t know what it’s like to hit “publish” while your stomach churns with nerves, only to get a message later that says, “This made me feel less alone.”
Flawlessness might be a machine’s strength. But humanity is ours.
The very things I used to try to hide—the quirks, the rough edges, the imperfections—are the things that make my work worth sharing.
A Different Kind of Readiness
I used to think I needed to wait until something was “ready.” The blog post polished just right. The podcast that’s perfectly edited. The message refined until it couldn’t possibly be criticized.
But I’ve learned that readiness is a mirage. It’s often just perfectionism in disguise.
The truth is, most of the things that resonated most with people—my most-downloaded podcast episode, the articles that readers emailed me about months later—were the ones I almost didn’t share. The ones that felt too messy, too vulnerable, too real.
And yet, those are the ones people said, “This is exactly what I needed to hear.”
Not the flawless ones. The human ones.
How We Can Embrace Imperfection
I’m not saying it’s easy. Perfectionism is sneaky. It wears the disguise of “high standards” or “being thorough.”
Here’s what I’ve found helps me. Not rules, but reminders I keep returning to:
Share before you feel ready.If it feels 80% good enough, release it. The last 20% is often just endless polishing.
Reframe mistakes as stories.My table’s flaws? Now they’re conversation starters. What mistakes of yours might carry meaning, too?
Notice where imperfection builds connection.The things that make people feel closer to you usually aren’t the shiny parts. They’re the honest ones.
The Bigger Picture
We live in a culture obsessed with speed, optimization, and polish. AI accelerates that pressure. It tempts us to compete on machine terms: flawless, instant, infinite.
But that’s not the game we’re meant to play.
Our advantage—our only real advantage—is that we’re human. We bring nuance, empathy, humor, vulnerability, and lived experience.
Robots don’t laugh until they snort. They don’t ugly cry during Pixar movies. They don’t mismeasure wood or forget to use the wood glue and build a table that their partner loves anyway.
You do. I do. That’s the point.
So maybe we don’t need to sand down every rough edge. Perhaps we don’t need to hide every flaw.
Because when the world is flooded with flawless, machine-polished work, the imperfect, human things will stand out.
Chris Cage is the author ofStill Human: Staying Sane, Productive, and Fully You in the Age of AI.He is a product manager, writer, and mental health advocate. He writes at The Mental Lens blog and hosts the podcast Through the Mental Lens, where he explores the intersection of productivity, mental well-being, and technology. Learn more and subscribe to the newsletter atTheMentalLens.com. You can also follow Chris on Instagram, Goodreads, and Amazon.
For the past four years, the conversation about AI and software development has moved faster than most people can track. Every week, there is a new tool, a new benchmark, a new paper, or a new claim about what AI will or won’t replace. There is certainly noise, but even if sometimes data seems inconclusive or contradictory, we still know more now than three years ago about AI adoption.
With four years of AI adoption under our belt, we are also able to start seeing the shift in what it means to be a software developer. I lead key research initiatives at GitHub where I focus especially on understanding developers’ behavior, sentiment, and motivations. The time we are in with AI is pivotal, and I interview developers regularly to capture their current perspective. Most recently I conducted interviews to understand how developers see their identity, work, and preferences change as they work more closely than ever with AI.
The TL;DR? The developers who have gone furthest with AI are working differently. They describe their role less as “code producer” and more as “creative director of code,” where the core skill is not implementation, but orchestration and verification. Let’s dive in for the more detailed findings, alongside key stats from the 2025 Octoverse report.
2023: Curiosity, hesitation, and identity questions
Two years ago, we interviewed developers to understand their openness to having AI more deeply integrated into their workflow. At the time, code completions had become mainstream and agents were only a whisper in the AI space. Back then, we found developers eager to get AI’s help with complex tasks, not just filling in boilerplate code. Developers were most interested in:
Summaries and explanations to speed up how they make sense of code related to their task, and
AI-suggested plans of action that reduce activation energy. In contrast, developers wanted AI to stay at arm’s length (at least) on decision-making and generating code that implements whole tasks.
The explanation of that qualitative trend from 2023 is important. At the time, AI was seen as still unreliable for large implementations. But there was more to the rationale. Developers were reluctant to cede implementation because it was core to their identity.
That was our baseline in 2023, which we documented in a research-focused blog. Since then, developers’ relationship with AI has changed (and continues to evolve), making each view a snapshot. That makes it critical to update our understanding as the tools have evolved and developer behavior has consequently changed.
One of the interviewees in 2023 wrapped their hesitation in a question: “If I’m not writing the code, what am I doing?”
That question has been important to answer since then, especially as we hear future-looking statements about AI writing 90% of code. If we don’t describe what developers do if/when AI does the bulk of implementation, why would they ever be interested in embracing AI meaningfully for their work?
2025: Fluency, delegation, and a new center of gravity
Fast forward to this year: we interviewed developers again, and this time, we focused on advanced users of AI. This was, in part, because we found a growing number of influential developer blogs focused on agentic workflows. They described sophisticated setups over time, and signalled optimism around coding with and delegating to AI (see here, here, and here for just a few examples). It was important to capture that rationale, assess if/how it’s shared by more AI-experienced developers, and understand what fuels it.
The developers we spoke with described their agentic workflows and how they reached AI fluency: relentless trial-and-error and pushing themselves to use AI tools every day for everything.
That was their method for gaining confidence in their AI strategy, from identifying which tools would be helpful for which task to prompting and iterating effectively.
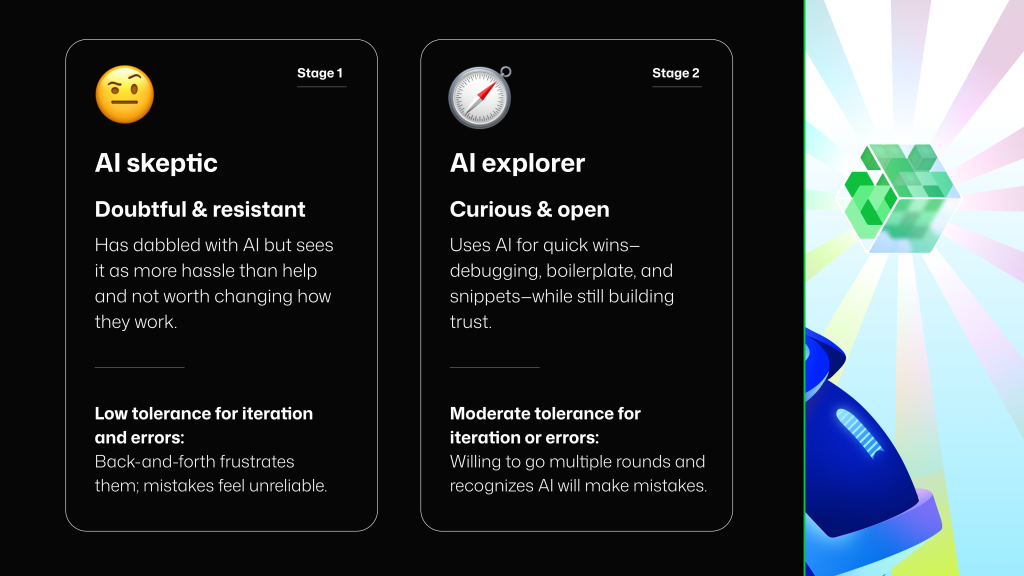
The tools did not feel magical or intuitive all the time, but their determination eventually led them to make more informed decisions: for example, when to work synchronously with an agent, when to have multiple agents working in parallel, or when to prompt an AI tool to “interview” them for more information (and how to check what it understands). None of these AI strategists started out that way. Most of them started as AI skeptics or timid explorers. As we synthesized the interviewees’ reported experiences, we identified that they matured in their knowledge and use of AI moving from Skeptic, to Explorer, to Collaborator, to Strategist.
Each stage came with a better understanding of capabilities and limitations, and different expectations around speed, iteration, and accuracy. A developer that used AI to co-create solutions (a stage we call “AI Collaborator”) knew to expect back-and-forth iteration with an agent. But when they were using exclusively code completions or boilerplate snippets (probably an “AI Skeptic”), they expected low-latency, one-shot success—or they quickly reverted to doing things without AI.
Interestingly, each stage in a developer’s comfort with AI had a matching evolution in the tools and workflows they felt ready to adopt: completions, then a chat and copy-paste workflow, then AI-enabled IDEs, and then multi-agent workflows. The advanced AI users we interviewed used several AI tools and agents in parallel, relying on a self-configured AI stack.
What looks from the outside like “new features” was, from the inside, a gradual widening of what developers were willing to delegate. By the time they reached that latest stage, the nature of their work had changed in a noticeable way.
At the Strategist stage, their development sessions looked very different from the days when they worked with AI as autocomplete. They focused less on writing code in the traditional sense, and more on defining intent, guiding agents, resolving ambiguity, and validating correctness. Delegation and verification became the primary activities as they felt the center of gravity shift in their work.
This transition is the identity shift. Developers who once wondered, “If I’m not the one writing the code, what am I doing?” now answer that question in practice: they set direction, constraints, architecture, and standards. They shift—using a phrase we first heard in interviews—from code producers to creative directors of code. And, crucially, the developers who reach this level do not describe it as a loss of craft but as a reinvention of it.
This shift is imperceivable unless experienced. The path to becoming AI-fluent is paved with trial and error, frustration, a gradual build up of trust, and ah-ha moments when steps start working as intended and become workflows. Most of the interviewees told us that their sentiment toward the future of software development changed only after they saw the shift in their own work. What once felt like an existential threat began to feel like a strategic advantage. Their outlook became more optimistic as they learned how to use AI tools with confidence and agency.
Ecosystem signals that reinforce the shift
These interviews are early signals about the impact of AI in developer workflows from the most advanced users. But we are already seeing their practices diffuse outward. Developers are beginning to make different choices because AI is present in the workflow and they assume it will increase. Choices about abstractions, code style, testing strategy, and even programming languages are shifting as developers adjust to a world where delegation is normal and verification is foundational.
The 2025 Octoverse report captured one striking example of this shift: TypeScript became the #1 programming language by monthly contributors on GitHub in August 2025. Many factors influence language popularity, but this particular rise says something important about the developer–AI relationship. TypeScript brings clarity and structure to a codebase, expresses intent more explicitly, and provides a type system that helps both developers and AI reason about correctness. In interviews, developers mentioned needing to give AI more guardrails and more context to reduce ambiguity and make verification easier. When AI writes large proportions of code, languages that enforce structure and surface errors early become a strategic choice. The shift toward TypeScript is a way of choosing languages that make delegation safer.
We also saw another telling signal in Octoverse: 80% of new developers on GitHub in 2025 used Copilot within their first week. This signals that developers are getting their first contact with AI at the beginning of their journey. If early contact brings early confidence, we may see developers reach more advanced stages of AI maturity sooner than previous cohorts did.
Another compelling data point was shared at GitHub Universe this year: within the first five months of the release of Copilot coding agent, GitHub’s autonomous agent that can generate pull requests, issues, or tasks, developers used it to merge more than 1 million pull requests.
Each one of those pull requests represents a small story of delegation and verification. A developer had to imagine the change, articulate intent, decompose the task, provide context, and set boundaries. They had to review, test, and validate the output before merging. Seen collectively, these pull requests are a measure of developers stepping into a new role. They show developers trying AI with increasingly meaningful units of work, and they show developers gradually building trust while taking responsibility for ensuring those units are correct.
That brings us to the natural next question: what skills support this new identity and role?
The skills that support developers’ new role
As delegation and verification become the focus, the skills developers will need to rely on shift upward. The work moves from implementation to three layers where developers focus, described below: understanding the work, directing the work, and verifying the work. Across interviews, developers consistently described strengths in all three layers as essential to working confidently with AI.
1. Understanding the work
These skills help developers determine what needs to be built, why, and how to shape the problem before any code comes into play.
AI fluency
Developers need an intuitive grasp of how different AI systems behave: what they are good at, where they fail, how much context they require, and how to adjust workflows as capabilities evolve. This fluency comes from repeated use, experimentation, and pattern recognition. With increased AI fluency developers are able to compose their AI stack: tools and features that they use for different projects and tasks, or in parallel configurations for end-to-end workflows.
Fundamentals
Even as AI takes on more implementation, deep technical understanding remains essential for developers. Knowledge of algorithms, data structures, and system behavior enables developers to evaluate complex output, diagnose hidden issues, and determine whether an AI-generated solution is sound.
Product understanding
Developers will need to increasingly think at the level of outcomes and systems, not snippets. This includes understanding user needs, defining requirements clearly, and reasoning about how a change affects the product as a whole. Framing work from an outcome perspective ensures what is delegated to AI aligns with the actual goals of the feature or system.
2. Directing the work
These skills enable developers to guide AI systems, tools, and agents so that the work moves forward effectively and safely.
Delegation and agent orchestration
Effective delegation requires clear problem framing, breaking work into meaningful units, providing the right context, articulating constraints, and setting success criteria. Advanced developers also decide when to collaborate interactively with an agent, versus running tasks independently in the background. Strong communication—precise, thorough, and structured—turns delegation into a repeatable practice.
Developer–AI collaboration
Synchronous collaboration with agents depends on tight, iterative loops: setting stopping points, giving corrective feedback, asking agents to self critique, or prompting them to ask clarifying questions. Some developers described instructing agents to interview them first, as a way to build shared understanding before generating any code.
Architecture and systems design
As AI handles more low-level code generation, architecture becomes even more important. Developers design the scaffolding around the work: system boundaries, patterns, data flow, and component interactions. Clear architecture gives agents a safer, more structured environment and makes integration more reliable.
3. Verifying the work
This skill category is becoming part of the defining center of the developer role: ensuring correct and high-quality outputs.
Verification and quality control
AI-generated output requires rigorous scrutiny. Developers validate behavior through reviews, tests, security checks, and assumption checking. Many reported spending more time verifying work than generating it, and feeling this was the right distribution of effort. Strong verification practices are what make larger-scale delegation possible, and allow developers to gradually trust agents with meaningful units of work.
Verification always was a step of the process, usually at the end. In AI-supported workflows, it becomes a continuous practice.
Annie Vella, a Distinguished Engineer at Westpac NZ, recently wrote an exceptional post about how the software engineer role changes with AI and the new competency map for engineers building systems with LLMs and agents. Annie’s experience (and research) share many similarities with the findings from our interviews with advanced AI users. A worthy read!
This year’s snapshot
What started as curiosity has now become preparedness. Developers see their profession changing in real time. They believe that AI will continue to evolve rapidly, and that the pace of change will not slow. Many are adapting to the change by building AI fluency, practicing confident orchestration of tools and agents, and treating delegation and verification as core parts of their craft. They see these skills as a competitive advantage, one that will define the next era of software development.
The value of a developer is shifting toward judgment, architecture, reasoning, and responsibility for outcomes, moving their work up the ladder of abstraction. As we build tools to support developers and look to measure AI’s impact, it’s important that our perspective matches the evolution of their work and identity.
How to track the evolving landscape
There is no single source of truth for how AI is changing software development, but there are reliable signals:
Large-scale data reports (such as GitHub’s Octoverse report) show macro-level adoption and behavior patterns.
Longitudinal industry studies (e.g., DORA) reveal where productivity gains stall or compound.
Field research and developer interviews help us interpret big data correctly and identify trends before we see them at scale.
In this round of interviews, we recruited 22 US-based participants working full time as software engineers. We used the Respondent.io platform for recruitment, and there was no requirement for interviewees to be GitHub users. Participants were selected based on a screener that assessed the depth and breadth of their AI use. We included only those who used AI for more than half of their coding work, used at least four AI tools from the thirteen we listed, and indicated experience with all of the advanced AI-assisted development activities included in the screener.
Participants worked in organizations of various sizes (55% in large or extra-large enterprises, 41% in small- or medium-sized enterprises, and 4% in a startup). Finally, we recruited participants across the spectrum of years of professional experience (14% had 0-5 years of experience, 41% had 6-10 years, 27% had 11-15 years, and 18% had over 16 years of experience).
We are grateful to all the developers who participated in the interviews for their invaluable input.
Artificial intelligence has become very easy to access to the public, which has made it very popular. Artists all over are combining their skills and AI to create all kinds of edits. Even most apps have filters that use AI to make you look older, younger, or even a different gender.
This San Francisco-based graphics artist uses this new technology to see how famous paintings and cartoon characters would look if they were realistic, and how artificial intelligence recreates historical figures from paintings or portraits on money bills.
On his website, Nathan says: “I am a technical director, creative technologist, visual effects supervisor, and motion graphics artist with over a decade of experience. Currently exploring the intersection of art and AI.”
Nathan Shipley answered some questions for us. He told us what inspired him to create these edits: “On one side, I love to create impossible images and explore new technology. I’ve got a background in animation and visual effects and once I saw what is possible using AI and machine learning tools, I realized there are so many things that could be done with them that would otherwise be impossible. Even some things that may be technically possible with VFX and CG could still be very time-consuming or expensive, whereas AI enables entirely new possibilities.
On the other side, it’s fascinating to explore how an AI model built on a particular dataset with a particular framework can ‘see’ the world and then transform images. The AI ‘knows’ only what it has already seen and filters the world through this lens. Each little tweak to the dataset, the training parameters, the model, and the input imagery all have the possibility to change the output. This is a space to explore how artificial neural networks interpret the world in a way that can be similar to our own minds. I’m not saying that an image I created is what Mona Lisa actually looked like, but it is how the machine sees her based on this particular arrangement of variables. That, to me, is fascinating.
I also want to add that these are definitely just experiments and that there are some pretty obvious limitations of the AI and the datasets that it’s trained on. Frida loses her unibrow, Miles’ hair gets mangled, Lil Miquela’s freckles disappear, hats turn to hair, and Ben Franklin even gets an earring! These are just some examples of how this particular combination of variables recreates a face that comes with a lot of randomness and inconsistencies. Keeping diversity in AI is an area of active research.”
#2 Miles Morales From Spider-Man: Into The Spider-Verse
“I have always loved to draw, take photos, and paint. I’ve also always had a computer around since I was in elementary school using a 286 with MS-DOS and no hard drive. The combination of traditional art and technology has been a natural step for me and led to my career in VFX and animation.
My current interest in exploring face manipulation and generative art using AI and machine learning started with a project for the Salvador Dali museum called Dali Lives in 2018. I used early deepfake code to bring Dali back to the museum to talk to visitors about his art. From here, I moved into working with GANs and realized how powerful neural networks can be for image processing and generation! For me, creating art is both an expression of curiosity and an act of exploration through process.”
“My favorite part about creating art is the process of actually making it; the journey and all the exploration that goes with it. I love having a problem and no idea how I’m going to solve it, putting my headphones on, losing track of time, and just trying things until it works.
It’s great to see a finished image, but it’s even more exciting to try new code, use code in ways it wasn’t meant to be, combine different tools together, and create entirely new art through new processes.”
Nathan has a 4-year-old son and he loves to explore the world with him: “We fish, go to the beach, paint, draw, read, play baseball, and pretend. Otherwise, I love running—it calms me down and focuses my mind.”
The artist tells us more about himself: “I’m just a guy from the Midwest of the United States. I grew up in Indiana, went to Indiana University, and then worked doing animation for TV at the Indianapolis Motor Speedway. Eventually, I was ready to leave Indiana and go to California.
I was very fortunate to first have the opportunity to travel around the world for a year with no plan before moving to San Francisco. I flew to Lima, Peru on a one-way ticket and spent the next 12 months staying in a handful of cities in South America, Eastern Europe, Turkey, India, and Thailand. If I got to a place I liked, I got an apartment and stayed for a month.
Traveling, being curious about the world, and meeting many different people goes quite well with creating art and just living life in general.
I did eventually land in San Francisco, where I’ve spent the last 10 years working on animation, VFX, and creative technology projects at Google, Intel, and currently the ad agency Goodby, Silverstein & Partners.”
Nathan explains how he creates these edits: “It’s a very iterative and explorative process. In the most simple terms, a face is used as input for the software and the software generates new faces based on the input. I have examples where I am creating ‘real’ versions of painted or cartoon people and also cartoon versions of real people.
More specifically, to create real people, the central part of the process uses machine learning to find a human who has a similar shape to the faces in an AI network created by Nvidia. This network is created with a GAN (a kind of machine learning framework, this GAN is called StyleGAN) and trained on a dataset of 70,000 human faces (called FFHQ). The AI learns how to generalize what a human face looks like and can then generate new human faces that don’t actually exist but look very realistic.
Because the network is trained on images of real people, it’s very good at creating more real people, even when you give it an input that is just a drawing or painting.
I have other examples using the same tool (StyleGAN) to create new images based on 400-year-old woodcuts of Aesop’s Fables illustrations, Beeple’s library of everydays, and even custom datasets to make music videos for musicians like Qrion and Hiatus. A lot of these are on my site here.”
“I have a core set of tools that I use from my background in animation and VFX (Photoshop, After Effects, C4D, Maya, Nuke) but the most interesting tools usually come from Github repos released by academics and machine learning researchers. These are often run by editing Python code on a Linux machine which controls a machine learning library like Tensorflow or PyTorch.
In fact, almost everything about these face images comes directly as output from the Python code. I’ve been particularly interested in exploring Nvidia’s StyleGAN and a StyleGAN encoder called pixel2style2pixel.”
Nathan says that the actual images take minutes to create; however, he had to go a long way to learn everything: “All of the learning and background I needed to get to this point has been a couple years of exploration and trial and error. I even attended a conference at MIT called GANocracy back in 2019.
I’ve built an art player, for example, that can generate completely new, never-ending, totally novel art in real time. Frames are made on the fly! However, training the model and writing the code for the player was weeks of work and processing time.”
The artist shared how he chooses which people or characters to recreate: “I pick characters that I love (Miguel from Coco, for example) or historic people that we don’t actually have photographs of. Some faces don’t work as well as others, but it’s really exciting when there is a compelling result! A lot of this is trial and error and me just publicly sharing the tests that I make as I go.
For example, I would love to see what Mona Lisa might look like and now I’ve got a realistic face that might be like her. I’m not saying that it is Mona Lisa, but it’s a possibility.
When people see my edits, they say everything from ‘amazing!’ to ‘creepy!’ to ‘that looks like my cousin!’ They seem to be getting a good amount of attention, so at the very least, they’re interesting!”
“Overall, I think the space of generative and AI art is a fascinating and very deep well to explore. I’d certainly encourage readers that are interested to try it out! The technical hurdles can seem daunting, but with a little bit of background, you can really Google your way through a lot of this.
It’s also the sort of thing where academics and researchers present these technologies in a very academic or complicated-sounding way. Understanding a paper called ‘A Style-Based Generator Architecture for Generative Adversarial Networks’ can seem daunting. However, seeing imagery created by artists with the same technology can be very inspiring!
I’d highly encourage readers to check out the work of Memo Akten, Scott Eaton, Mario Klingemann, Refik Anandol, Helena Sarin, and Ben Snell to name just a few. These are the artists that have been foundational in my own interest in exploring AI and machine learning.”
What do you think of these edits? Tell us in the comments and vote for your favorite ones! Don’t forget to go show some love to the artist on his social media accounts.
If you want to see more posts similar to this one, click here or here!
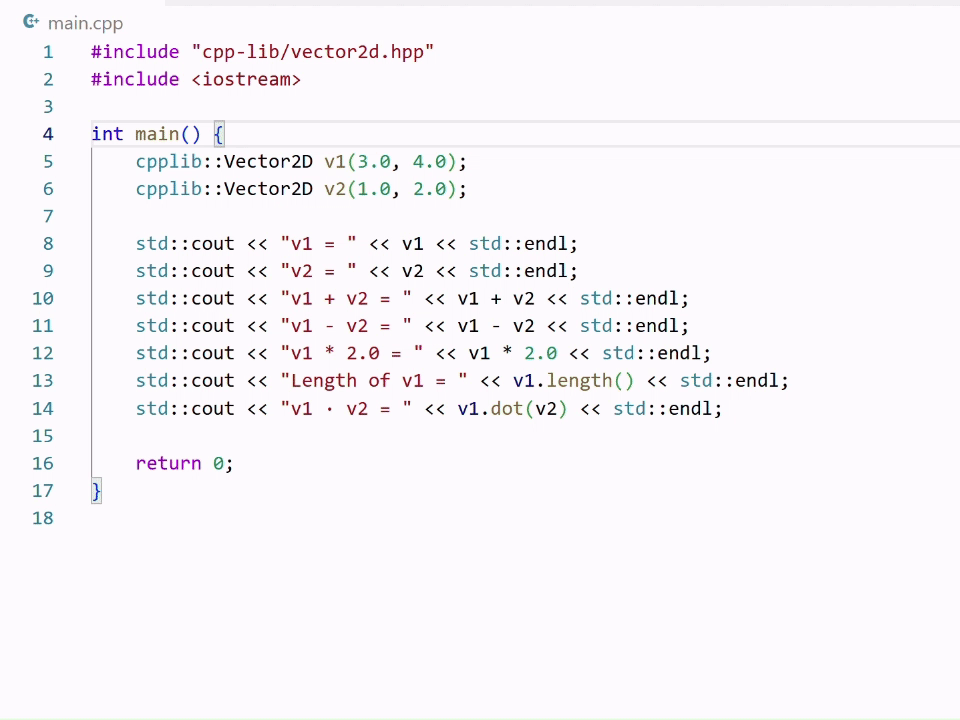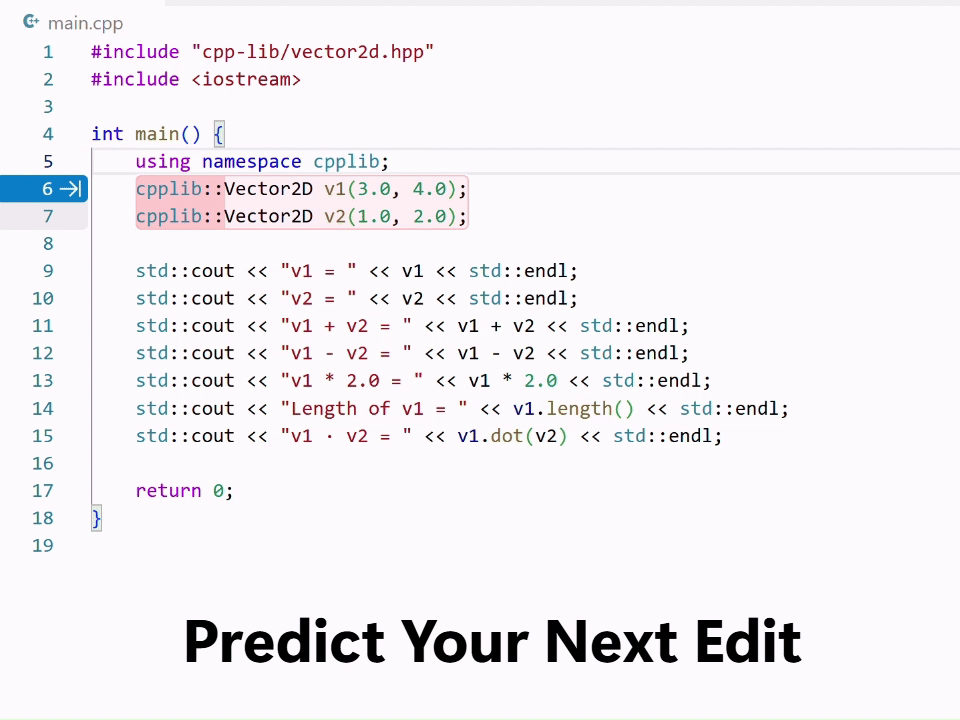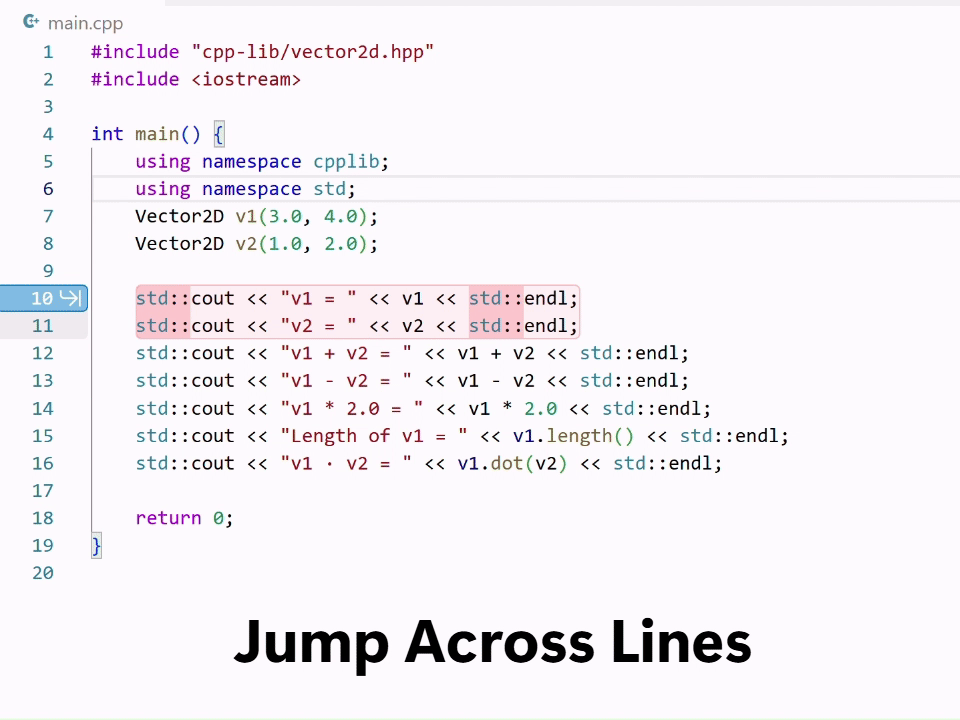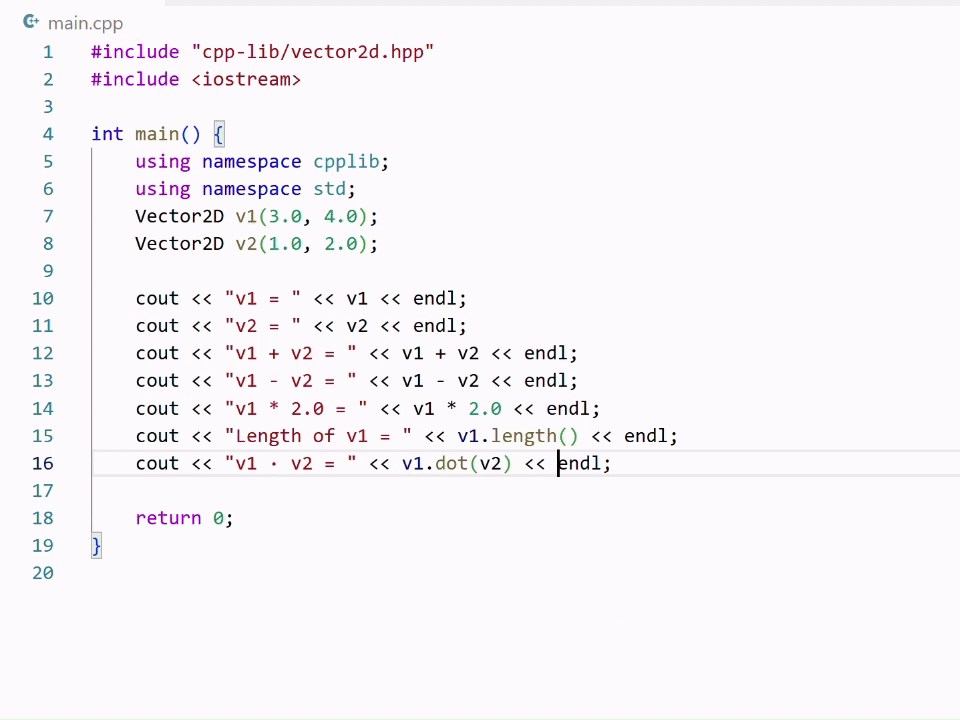
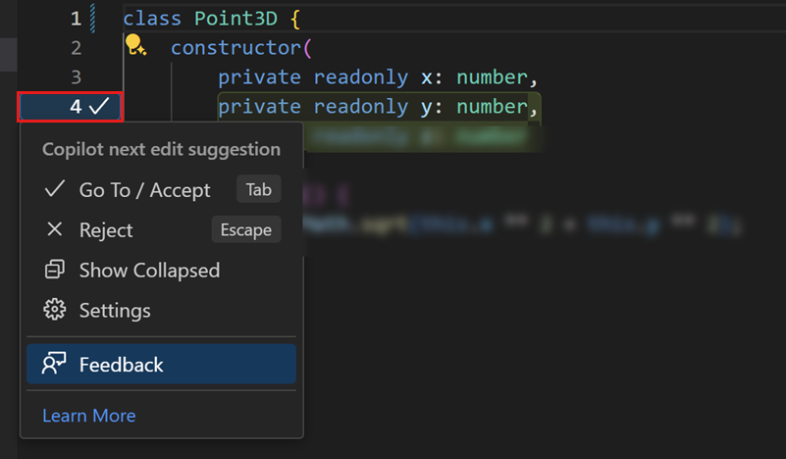
Editing code often involves a series of small but necessary changes ranging from refactors to fixes to cleanup and edge-case handling. In February, we launched next edit suggestions (NES), a custom Copilot model that predicts the next logical edit based on the code you’ve already written. Since launch, we’ve shipped several major model updates, including the newest release earlier this month.
In this post, we’ll look at how we built the original model, how we’ve improved it over time, what’s new, and what we’re building next.
Why edit suggestions are challenging
Predicting the next edit is a harder problem than predicting the next token. NES has to understand what you’re doing, why you’re doing it, and what you’ll likely do next. That means:
The model must respond quickly to keep up with your flow.
It has to know when not to suggest anything (too many suggestions can break your focus).
It must infer intent from local context alone without your explicit prompts.
It must integrate deeply with VS Code so suggestions appear exactly where you expect them.
Frontier models didn’t meet our quality and latency expectations. The smaller ones were fast but produced low-quality suggestions, while the larger ones were accurate but too slow for an in-editor experience. To get both speed and quality, we needed to train a custom model.
NES isn’t a general-purpose chat model. It’s a low-latency, task-specific model that runs alongside the editor and responds in real time. It’s the result of aligning model training, prompting, and UX around a single goal: seamless editing inside the IDE. That required tight coordination between model training, prompt design, UX design, and the VS Code team—the model only works because the system was co-designed end-to-end.
This “AI-native” approach where every part of the experience evolves together is very different from training a general-purpose model for any task or prompt. It’s how we believe AI features should be built: end to end, with the developer experience at the center.
How we trained
The hard part wasn’t the architecture; it was the data. We needed a model that could predict the next edit a developer might make, but no existing dataset captured real-time editing behavior.
Our first attempt used internal pull request data. It seemed reasonable: pull requests contain diffs, and diffs look like edits. But internal testing revealed limitations. The model behaved overly cautiously—reluctant to touch unfinished code, hesitant to suggest changes to the line a user was typing, and often chose to do nothing. In practice, it performed worse than a vanilla LLM.
That failure made the requirement clear: we needed data that reflected how developers actually edit code in the editor, not how code looks after review.
Pull request data wasn’t enough because it:
Shows only the final state, not the intermediate edits developers make along the way
Lacks temporal ordering, so the model can’t learn when changes happen
Contains almost no negative samples (cases where the correct action is “don’t edit”)
Misses abandoned edits, in-progress rewrites, and other common editing behavior
So we reset our approach and built a much richer dataset by performing a large-scale custom data collection effort that captured code editing sessions from a set of internal volunteers. We found data quality to be key at this stage: a smaller volume of high-quality edit data led to better models than those trained with a larger volume of data that was less curated.
Supervised fine-tuning (SFT) of a model on this custom dataset produced the first model to outperform the vanilla models. This initial model provided a significant lift to quality and served as a foundation for the next several NES releases.
Model refinement with reinforcement learning
After developing several successful NES models with SFT, we focused on two key limitations of our training approach:
SFT can teach the model what constitutes a good edit suggestion, but it cannot explicitly teach the model what makes an edit suggestion bad.
SFT can effectively leverage labeled edit suggestions, but it cannot fully utilize the much larger number of unlabeled code samples.
To address these two limitations, we turned to reinforcement learning (RL) techniques to further refine our model. Starting with the well-trained NES model from SFT, we optimized the model using a broader set of unlabeled data by designing a grader capable of accurately judging the quality of the model’s edit suggestions. This allows us to refine the model outputs and achieve higher model quality.
The key ideas in the grader design can be summarized as follows:
We use a large reasoning model with specific grading criteria.
We routinely analyze model outputs to update the grading criteria, constantly searching for new qualities that indicate unhelpful edits.
The grader should not only consider the correctness of the edit suggestion, but also strive to make the code diff displayed in the UI more user-friendly (easy to read).
Continued post-training with RL has improved the model’s generalization capability. Specifically, RL extends training to unsupervised data, expanding the volume and diversity of data that we have available for training and removing the requirement that the ground truth next edit is known. This ensures that the training process consistently explores harder cases and prevents the model from collapsing into simple scenarios.
Additionally, RL allows us to define our preferences through the grader, enabling us to explicitly establish criteria for “bad edit suggestions.” This enables the trained model to better avoid generating bad edit suggestions when faced with out-of-distribution cases.
Lessons from training our latest custom NES model
Our most recent NES release builds on that foundation with improvements to data, prompts, and architecture:
Prompt optimization: NES runs many times per minute as you edit, so reducing the amount of context we send on each request has a direct impact on latency. We trimmed the prompt, reused more cached tokens between calls, and removed unneeded markup, which makes suggestions appear faster without reducing quality.
Data quality filtering: Used LLM-based graders to filter out ambiguous or low-signal samples in order to reduce unhelpful or distracting suggestions.
Synthetic data: Distilled data from larger models to train a smaller one without losing quality.
Hyperparameter tuning: Tuned hyperparameters for the new base architecture to optimize suggestion quality.
How we evaluate model candidates
We train dozens of model candidates per month to ensure the version we ship offers the best experience possible. We modify our training data, adapt our training approach, experiment with new base models, and target fixes for specific feedback we receive from developers. Every new model goes through three stages of evaluation: offline testing, internal dogfooding, and online A/B experiments.
Offline testing: We evaluate models against a set of targeted test cases to understand how well they perform in specific scenarios.
Internal dogfooding: Engineers across GitHub and Microsoft use each model in their daily workflows and share qualitative feedback.
A/B experiments: Subject the most promising candidates to a small percentage of real-world NES requests to track acceptance, hide, and latency metrics before deciding what to ship.
Continuous improvements
Since shipping the initial NES model earlier this year, we’ve rolled out three major model updates with each balancing speed and precision.
April release: This release strongly improved model quality and restructured the response format to require fewer tokens. The result? Faster, higher-quality suggestions.
May release: To address developer feedback that NES was showing too many suggestions, we improved suggestion quality and reduced the model’s eagerness to make changes. This led to more helpful suggestions and fewer workflow disruptions.
November release: After testing nearly thirty candidate models over the summer—none of which were strong enough to replace the May model—this release finally cleared the bar in A/B testing. It delivers higher-quality suggestions with lower latency by shortening prompts, reducing response length, and increasing token caching.
The table below summarizes the quality metrics measured for each release. We measure the rate at which suggestions are shown to developers, the rate at which developers accept suggestions, and the rate at which developers hide the suggestion from the UI. These are A/B test results comparing the current release with production.
Release
Shown rate
Acceptance rate
Hide rate
April
+17.9%
+10.0%
-17.5%
May
-18.8%
+23.2%
-20.0%
November
-24.5%
+26.5%
-25.6%
Community feedback
Developer feedback has guided almost every change we’ve made to NES. Early on, developers told us the model sometimes felt too eager and suggested edits before they wanted them. Others asked for the opposite: a more assertive experience where NES jumps in immediately and continuously. Like the tabs-vs-spaces debate, there’s no universal preference, and “helpful” looks different depending on the developer.
So far, we’ve focused on shipping a default experience that works well for most people, but that balance has shifted over time based on real usage patterns:
Reducing eagerness: We added more “no-edit” samples and tuned suggestion thresholds so the model only intervenes when it’s likely to be useful, not distracting.
Increasing speed: Because NES runs multiple times per minute, we continue to reduce latency at the model, prompt, and infrastructure levels to keep suggestions inside the editing flow.
Improving developer experience: We refined how edits are displayed, so suggestions feel visible but not intrusive, and expanded settings that let developers customize how NES behaves.
Looking ahead, we’re exploring adaptive behavior where NES adjusts to each developer’s editing style over time, becoming more aggressive or more restrained based on interaction patterns (e.g., accepting, dismissing, or ignoring suggestions). That work is ongoing, but it’s directly informed by the feedback we receive today.
As always, we build this with you. If you have thoughts on NES, our team would love to hear from you! File an issue in our repository or submit feedback directly to VS Code.
What’s next
Here’s what we’re building:
Edits at a distance: Suggestions across multiple files—not just where you’re typing.
Faster responses: Continued latency improvements across the model and infrastructure.
Smarter edits: Better anticipation of context and cross-file dependencies.
To experience the newest NES model, make sure you have the latest version of VS Code (and the Copilot Chat extension), then ensure NES is enabled in your VS Code settings.
Acknowledgements A special thanks to Yuting Sun (CoreAI Post Training), Zeqi Lin (Core AI Post Training), Alexandru Dima (VS Code), Brigit Murtaugh (VS Code), and Soojin Choi (GitHub Copilot) for contributing to this blog post. We would also like to express our gratitude to the developer community for their continued engagement and feedback as we improve NES. Also, a massive thanks to all the researchers, engineers, product managers, and designers across GitHub and Microsoft who contributed (and continue to contribute) to model training, client development, infrastructure, and testing.
Sometimes geothermal hot spots are obvious, marked by geysers and hot springs on the planet’s surface. But in other places, they’re obscured thousands of feet underground. Now AI could help uncover these hidden pockets of potential power.
A startup company called Zanskar announced today that it’s used AI and other advanced computational methods to uncover a blind geothermal system—meaning there aren’t signs of it on the surface—in the western Nevada desert. The company says it’s the first blind system that’s been identified and confirmed to be a commercial prospect in over 30 years.
Historically, finding new sites for geothermal power was a matter of brute force. Companies spent a lot of time and money drilling deep wells, looking for places where it made sense to build a plant.
Zanskar’s approach is more precise. With advancements in AI, the company aims to “solve this problem that had been unsolvable for decades, and go and finally find those resources and prove that they’re way bigger than previously thought,” says Carl Hoiland, the company’s cofounder and CEO.
To support a successful geothermal power plant, a site needs high temperatures at an accessible depth and space for fluid to move through the rock and deliver heat. In the case of the new site, which the company calls Big Blind, the prize is a reservoir that reaches 250 °F at about 2,700 feet below the surface.
As electricity demand rises around the world, geothermal systems like this one could provide a source of constant power without emitting the greenhouse gases that cause climate change.
The company has used its technology to identify many potential hot spots. “We have dozens of sites that look just like this,” says Joel Edwards, Zanskar’s cofounder and CTO. But for Big Blind, the team has done the fieldwork to confirm its model’s predictions.
The first step to identifying a new site is to use regional AI models to search large areas. The team trains models on known hot spots and on simulations it creates. Then it feeds in geological, satellite, and other types of data, including information about fault lines. The models can then predict where potential hot spots might be.
One strength of using AI for this task is that it can handle the immense complexity of the information at hand. “If there’s something learnable in the earth, even if it’s a very complex phenomenon that’s hard for us humans to understand, neural nets are capable of learning that, if given enough data,” Hoiland says.
Once models identify a potential hot spot, a field crew heads to the site, which might be roughly 100 square miles or so, and collects additional information through techniques that include drilling shallow holes to look for elevated underground temperatures.
In the case of Big Blind, this prospecting information gave the company enough confidence to purchase a federal lease, allowing it to develop a geothermal plant. With that lease secured, the team returned with large drill rigs and drilled thousands of feet down in July and August. The workers found the hot, permeable rock they expected.
Next they must secure permits to build and connect to the grid and line up the investments needed to build the plant. The team will also continue testing at the site, including long-term testing to track heat and water flow.
“There’s a tremendous need for methodology that can look for large-scale features,” says John McLennan, technical lead for resource management at Utah FORGE, a national lab field site for geothermal energy funded by the US Department of Energy. The new discovery is “promising,” McLennan adds.
Big Blind is Zanskar’s first confirmed discovery that wasn’t previously explored or developed, but the company has used its tools for other geothermal exploration projects. Earlier this year, it announced a discovery at a site that had previously been explored by the industry but not developed. The company also purchased and revived a geothermal power plant in New Mexico.
And this could be just the beginning for Zanskar. As Edwards puts it, “This is the start of a wave of new, naturally occurring geothermal systems that will have enough heat in place to support power plants.”